<< 2025-02-09 | 2025-02-11 >>
工作
成果和进展:
明日工作安排:
- 准备下周一(2025-02-17)与苏州喜得供应商会谈一下,明确吹脱塔和吸收塔的具体细节。
复盘:
- 开年刚上班回来,
生活
流水账:
- 早上在 7:35 准时被闹钟叫醒,稍微缓了缓才起床。和昨天一样,先煮了鸡蛋,但因为没有玉米了,改为泡了一碗糙面,再加上一杯纯牛奶,确保了早餐的健康和均衡。
- 到公司后稍作休息,便开始回顾之前的工作,特别是年前写的《h 化学镍水氨氮吹脱工艺设计》,再配上相关的计算公式和文献重新阅读,帮助自己回忆起一些重要的细节。
- 接下来就开始摸鱼,研究了一下 Cursor——一款 AI 辅助编程软件,旨在利用大模型自动化程序编写和项目管理。先从官网下载安装了这款软件,因为免费计划有时限,所以又配置了自己的 API,并研究如何连接 ChatGPT、Gemini 和 Claude 的 AI 服务。由于身处国内,使用这些服务需要通过代理,因此下午花了很久在研究这个。最初,尝试使用中转 API,市面上有很多成熟的方案,但为了保证数据安全,我选择了开源项目,并在自己的 NAS 上部署了中转服务。虽然测试时能正常使用 API,但代理地址需要手动填写,并且单独使用中转 API 会遇到一些问题,因此我放弃了这个方法。随后换了个思路,选择了 GitHub 上的一个开源项目,能通过不同的代理服务连接各类 API。于是成功配置并部署了这个方法,唯一的缺点是每次使用时需要在链接中附加各服务的名称,操作上稍显繁琐,但基本能接受。
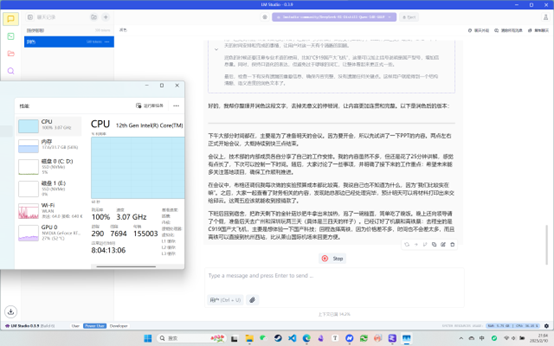
- 晚上在 B 站看到了一期视频,是关于 DeepSeek-R1 模型本地部署的,觉得很有兴趣,于是按照教程尝试了一下。没想到在下载模型时遇到了问题,由于服务器在国外,网速非常慢。于是通过百度找到方法,用阿里云的国内镜像源进行下载,速度稍有提升,但仍然只有 2MB/s。结果下载进行了一半,速度又掉到了 50KB/s,这下不知道怎么办了。然后想到国内也有资源库可以下模型,上网找了下 14B 的链接通过 IDM 下载,开始时速度也是 2MB/s。想着直连路由器可能会更快,试了一下网线直连笔记本,然而比 WiFi 还慢。所以后面用改回无线下载,又因为 IDM 不能续传重下的,没想到这次下载速度却到了 20MB/s,不久后 9 GB 的模型就下载完成了。用 LM Studio 加载好模型并设置参数后,我试用了下,发现响应速度非常快,感觉很满意。
- 这时我又想更大的 32B 模型会不会更好,但发现它体积确实有点大了,需要超过 20 GB 的存储空间。由于刚才下载时遇到问题,我决定将下载任务放到 NAS 上进行,想着无论速度快慢,反正迟早都能完成。然而,没想到网友们推荐的软件大多只支持 BT 下载,反而我这里的 HTTPS 直链无法下载。最后没辙了去问了 GPT-4o 得到了 Aira2 这个下载工具,果然可以支持直连,且速度稳定在 20 MB/s 以上,不到半小时就下载完了,这下是真的学到了。
- 晚上还看了一会儿猪猪直播,一场关于《Draw & Guess》的接龙版,总有人是非常的抽象哈哈。看完的时候也开始写日记,记录了 2025-02-08 的事情。
情绪:
感恩:
- 感激波哥给予的建议,不要过分追求完美。
- 感谢 GitHub 上的各个贡献者,尽管这次 one api.、new apiopenai proxy 等开源项目都没有用上,但是也是能解决代理问题的方法。
- 感谢笔吧评测室的详细教程,帮助我成功在本地部署了 DeepSeek-R1 模型。
- 感谢 LM Studio 这个软件,提供了在计算机本地发现、下载和运行 LLM 的工具。
- 感谢 魔搭社区 的模型库,能让我下载想要的大模型,且不限速。
- 感谢 Internet Download Manager 和 Aira2 这两个工具,其多线程下载功能跑满网速真的牛。
成就:
- 保持了健康的饮食,坚持减肥计划。
- 成功配置并部署了 Cursor,提升了编程的效率。
- 成功配置了反向代理,解决了使用国外 AI 服务的问题。
- NAS 是用到越来越顺了,现在部署项目、配置 SSL 证书和下载资源啥的,手拿把掐好吧。
- 在本地部署了 DeepSeek-R1 7B、14B 和 32B 的模型,还成功运行进行了交流。
- 补完了 2025-02-08 的内容,确保了个人记录的连续性和完整性。
反思:
思绪:
本地大模型效果
DeepSeek-R1 蒸馏过的 32B 的确实有点带不动,这 CPU 直接跑满了,内存也是大半了,每吐一个字得好几秒,还是 14B 的舒服一点,但效果也差了点,最好的还是官网的,满血是真的不一样。
Memos:
- 21:48 用 NAS 下东西就是快啊,网线直连路由器,正常就是 20+ MB/s,分分钟下完了都。 生活小技巧 daily-record ^1739195326
